L3C AI Briefing

Save the day: 21 May 2020, Glasgow, UК Over the course of the last year, L3C has established a fruit...




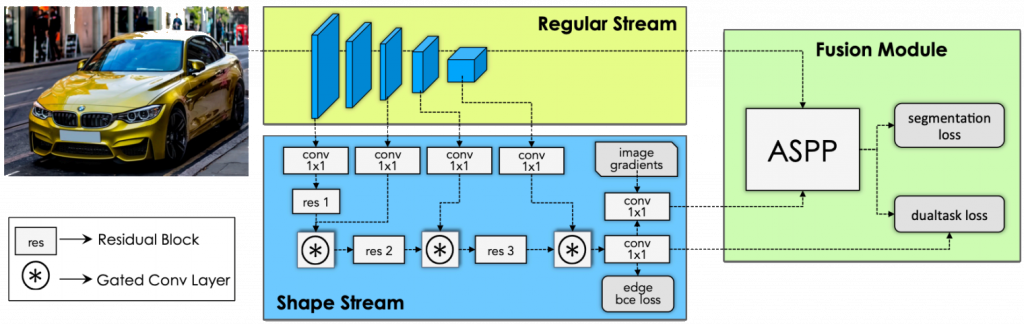




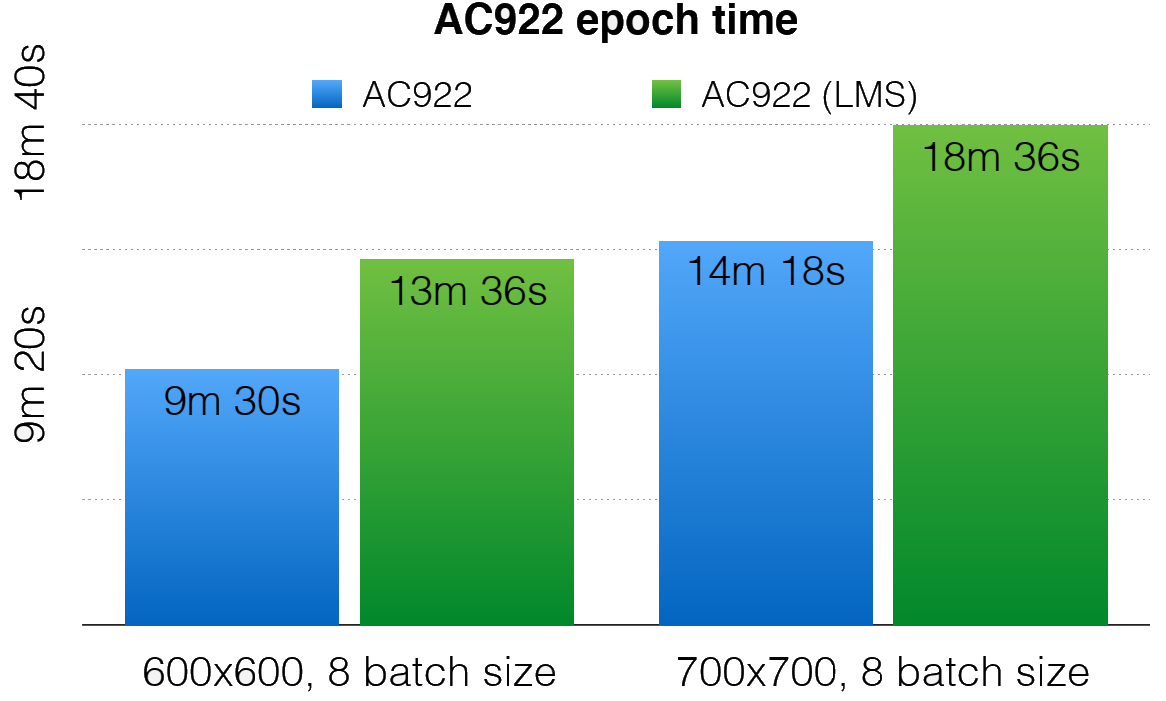
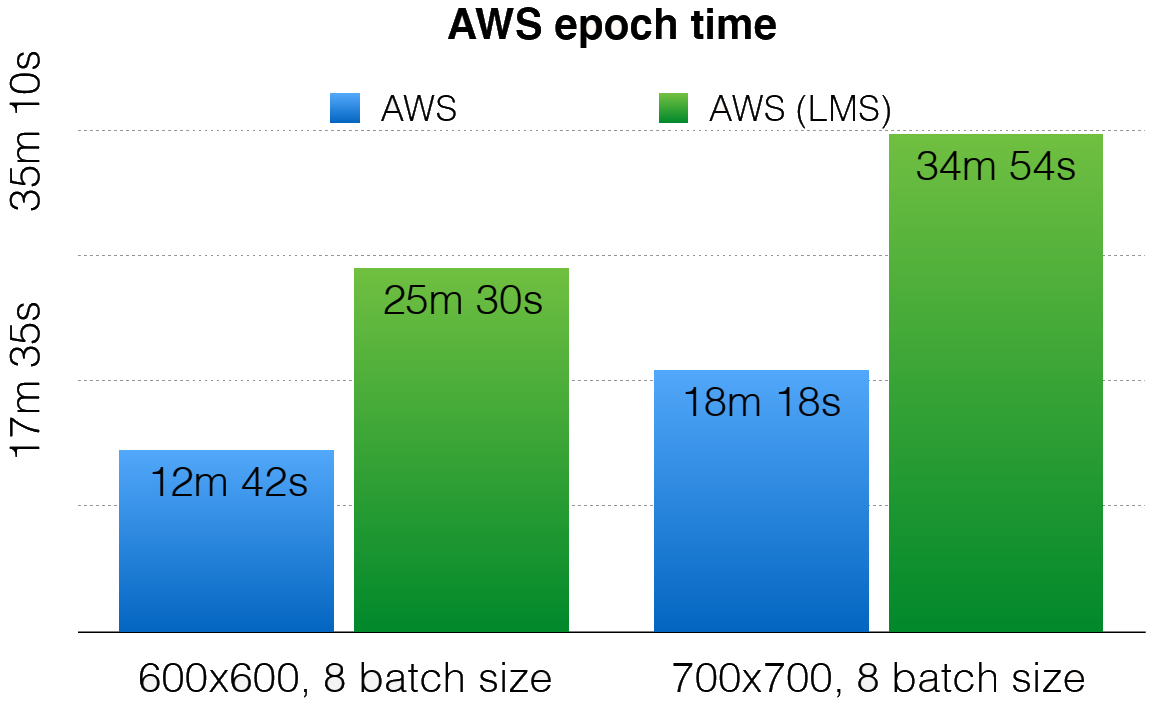
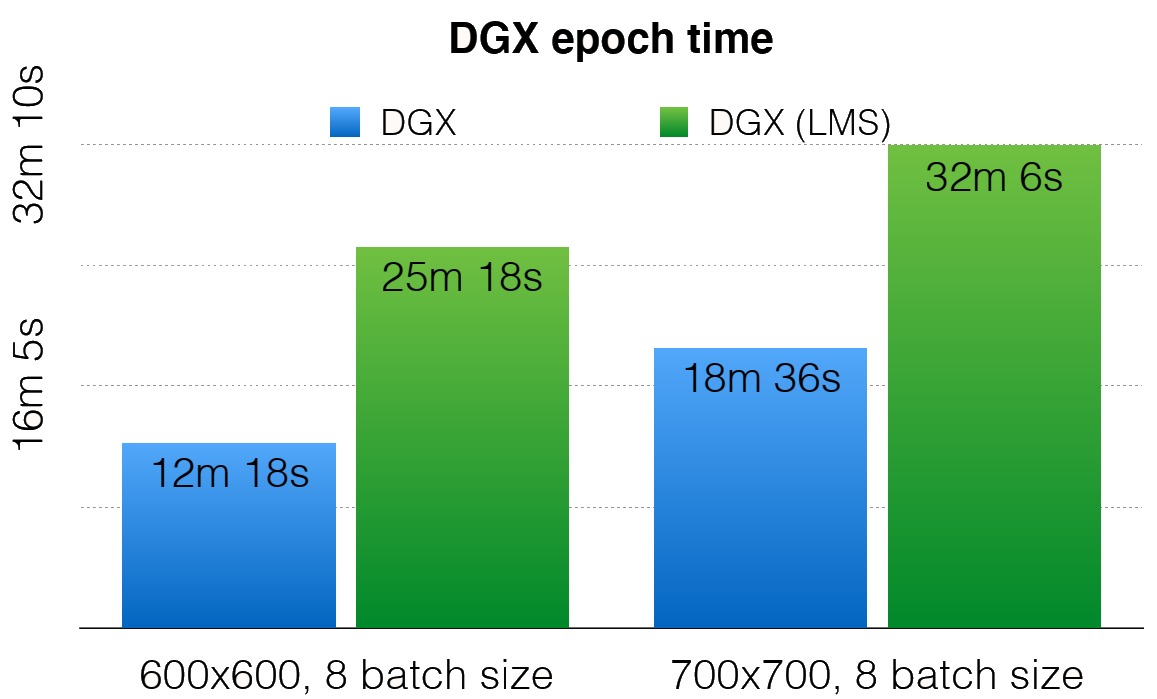

Save the day: 21 May 2020, Glasgow, UК Over the course of the last year, L3C has established a fruit...

Save the day: September 2020, London (Royal Society Medicine), UK In 2020, L3C is continuing its eff...

21 – 25 October 2019 | Prague, CZ Join IBM for a fantastic week of training and enablement on IBM...

16 October 2019 | OLYMPIA LONDON, UK In a period of unprecedented change, staying connected to techn...

Linux on Power and L3C As one of IBM’s Power Cloud partners, we have been always on the road of cons...
Most of you now on NVIDIA’s latest development direction – the so called RAPIDS librarie...

In a recent feed, we discussed the latest version of the IBM PowerAI. Now, IBM is announcing a few n...
Radiology is suffering one of the biggest staff shortages in the NHS which is causing patient delays...

IBM launched the latest version of its PowerAI Vision product on 15.03.2019. As most of you know, Po...

L3C were invited to speak at the healthcare strategy forum de-mystifying AI and sharing examples of...
![]()
AIX / Solaris / HPUX Cloud At Your Reach
7 Bell Yard, London WC2A 2JR
+44 0203 918 8910
office@l3c.cloud